Data Modeling
Personal notes and tips
These are personal notes. You are welcome to read them.
|
|
|
|
|
Management hints
|
HTML, javascript
|
Other
|
(best practises, risks, choosing software, ...)-
(scope, design, development, rollout)
-
(details on the scope and design phase)
-
-
|
|
|
| |
|
|
|
|
|
Contents
The Concepts
The Process
Some Products
Miscelaneous
|
|
Reference table, mandatory values in foreign key. The primary key is
in the reference table, the foreign key points to the primary key. The
reference table is the parent table; the child table holds the foreign
key to the parent table. See below for more on the one-to-many relationships.
Notations:
- The foreign key corresponds to one and only one row in the reference
table (shown with two bars). The row in the reference table corresponds
to none, one or many rows (shown with a zero and a crow's foot).
- Alternate notation: the arrow points from the foreign key to the primary
key.
- IDEF1X: a black dot indicates the child entity.
Note that if reference table contains a simple code and a meaning, then
it could be removed and the foreign key could be assigned to a domain.
|
|
|
This models a super-type/sub-type.
- The super-type or generic entity holds the common attributes
- Move the catagory specific attributes to sub-types.
- A sub-type discriminator field or a category discriminator
field is added to the super-type
- Both super-type and sub-type contain non-key attributes or foreign
keys. The foreign keys are always mandatory (see below). If foreign
keys are optional, they should be moved to sub-types.
- The primary key is the same for all entities. This leads to the consequence
that only one super-type is possible for any one entity (not like in
OO)
- Ideally, the sub-types should be nonoverlapping, i.e. occurrences
can be in only one or the other sub-type.
- Ideally, the sub-types should be exhaustive, i.e. no other category
exists other than those defined by the sub-types.
Note: a single sub-type is possible.
A subtype cluster is complete
when all possible subtype entities have been described. The subtype cluster
is incomplete
when not all entities have been discovered in the modeling process.
A subtype relationship is exclusive or non-overlapping
if the super-type can be related to only one sub-type. It is inclusive
or overlapping if a super-type can be related to more than one sub-type.
Related notions are generalization,
inheritance
and specialization.
|
|
|
 The "short-cut" relationship is redundant because of transitivity:
Remove the short-cut.
The "short-cut" relationship is redundant because of transitivity:
Remove the short-cut. |

 |
Recursive relationships can be also modelled with two tables. In one
of the tables, the primary key appears twice.
Recursive relationships are sometimes referred to as "fishhooks"
or "swine ears".
|
 |
In a hierarchy,
each instance can have zero to many subordinates, but a maximum of one
superior. Note that the top-most instance can also be modelled as self-referencing.
Because hierarchies are difficult to query, consider replacing with separate
entities if the hierarchy is only a few levels deep.
|
 |
In a network,
each instance has zero to many superiors and zero to many subordinates.
This is difficult to program and efforts should be made to continue talking
to the users to discover another way to model the entities.
|
 |
In a chain,
each instance is linked to at most one other instance. Model with a zero
to many (zero to two) relationship. Another option is to make another entity
that lists the instances in order. |
 |
Or constraint:
one table on the right OR the other is joined to the table on the left. |

 |
An arc or exclusive or
constraint means that only one or the other of the tables
on the right is joined to the table on the left.
Whenever possible, replace arcs with sub-types.
Arc in the primary key: trick is to put a surrogate key and have the arc on non-key fields. |
 |
In data modeling, aggregation
and composition
are modeled the same way. The notion is not as important as in UML. |
 |
Transferability:
related to change over time. Suppose a relationship between a person and
a radio license (see [2] P. 98 in bibliography). The relationship between
a person and the amateur radio license is non-transferable. The relationship
between a person and a commercial radio station license is transferable.
For transferable relationships, a history should be kept. Note that a transferable
one-to-one relationship is really a one-to-many when the time dimension
is considered. And a transferable one-to-many relationship can likewise
be seen as a many-to-many with changes over time. A non-transferable one-to-one
relationship will probably refer to the same real-world concept. A structured
key can be used to enforce nontransferability because nontransferability
is equivalent to weakness (see below). |
| |
A weak entity
is an entity that relies on another for its identification. In particular,
the primary key will be composite and contain the foreign key to another
entity. For example, the "Invoice Line" entity is a weak entity
if the foreign key to the "Invoice" entity is included in the
primary key. Note that nontransferability is equivalent to weakness (see
below). See also ER Diagrams. Note that weak entities
have rounded corners in IDEF1X notation. |
| |
An optional relationship means a partial
participation in the relationship. A mandatory relationship means
a total participation
in the relationship. |
Some more rules:
- Two entities should not have the same primary key (with the same meaning)
unless they are super-types/sub-types
- A dependant entity is an entity for which part of the primary key is the
primary key of another entity (multi-column PK, with one or more columns that
are the PK of the parent). The dependant entity depends on another for identification.
- A primary key is stable (no change of value), definitive, minimal (not large
or composite), accessible
- Optional attributes: ideally, the only fields with NULLs should be those
waiting for a value. When an attribute is always NULL, then it is optional.
See super-types/sub-types above. Move the optional attributes to a sub-type.
These attributes become mandatory for all instances of the sub-type. Define
a sub-type descriminator which is added to the super-type.
- A child entity is uses the entire primary key of the parent either as a
foreign key or as part of the primary key.
- In the case of artificial keys, alternate keys or selection attributes are
needed to identify instances.
- Relationships that are mandatory in both directions introduce a little constraint
when adding data. A row cannot be created on one side of the relationship
without creating the related row. Therefore, transactions should be used so
that the operation is seen as a whole and verified only once completed.
- Aggregation
- A derived attribute
is an attribute calculated from others. It has its place in a conceptual model,
but then could be removed in the logical and physical models.
- Complex attributes,
composed of two or more fields, such as addresses, names, foreign currency
amounts, need not be modelled in detail in the conceptual model.
- In a top-down approach, it may happen that an attribute is in fact multi-valued.
In the conceptual model, clearly make it as such with the attribute name in
plural and another indication. Then in the logical model, a separate table
will be built to model the multi-valued attribute.
Some aspects of the IDEF1X (Integration DEFinition for Information Modeling)
notation are described below in the section on Erwin. Basically,
the crow's feet are replaced with a black dot, because it is seen as the child
end of the relationship. In one-to-many relationships, a diamond indicates that
nulls are allowed on the "one" or parent side of the relationship.
(not to be confused with Idéfix:) 
Hint for determining relationship cardinality: count lines on the other side.
The difficulty is with the optionality of the Barker notation. The maxima are
"on the other side" and the optionality is on the "same side".
Two types of relationship rules: structural or cadinality rules and referential integrity rules.
The structural or cardinality rules define the existence (0 or 1 on the diagram).
The referential integrity rules define 1 or many on the diagram.
One to one relationships
In one-to-one relationships, two tables are joined. Generally, they share the
same primary key. This leads to an issue in the primary key generation: care
should be taken to generate the primary key for one table and copy the value
to the other. In addition, a foreign key relationship may have to be built in
to force integrity.
Very often, two tables with a one-to-one relationship can be merged into one
table. Exceptions are situations with a super type and sub-types. Another exception
is a transferable relationship which, after analysis, turns out to be one-to-many
relationship over time (at a given moment, the relationship is one-to-one, but
changes over time).
| Example |
Notation |
Barker Notation |
Comments |
 |
 |
 |
Loose relationship between the two tables (is it of any use?). |
 |
 |
 |
This needs a constraint to enforce the mandatory part of the relationship.
The instead of one-to-one optional relationship, use one table with nullable
columns.
Exception: super-type/sub-type. |
 |
 |
 |
This needs a constraint to enforce the mandatory relationship on both
sides.
A one-to-one mandatory relationship is very likely replaced by one table. |
One to many relationships
| Example |
Notation |
Barker Notation |
Comments |
 |
 |
 |
This is the most common situation, in particular when one table
references another table as a reference table. Another use is when a fact
table (on the right) references a dimension table (on the left) in data
warehouses. Note that here not all the values in the reference/dimension
table are used. They are available for future use.
Another notation uses an arrow:
 |
 |
 |
 |
When the relationship is optional on the side of the non-reference table
/ fact table, the foreign key can be null. This is not optimal and it is
best to resolve non-mandatory foreign key relationships (see below). Resolving
makes the diagram look like the previous row (1-to-1 with 0-to-many). |
 |
 |
 |
In this case, the relationship is mandatory on the side of the reference/dimension
table (compare with the first case above) and all rows in the reference/dimension
table are linked to a row in the other table. This needs an extra constraint
to be built in as the foreign key mechanism does not enforce this automatically.
This also implies the use of transactions so as to insert new values at
the same time on both sides. |
 |
 |
 |
This case combines both the difficulty of enforcing the mandatory relationship
on the side of the reference/dimension table (see previous row) and the
need to resolve the non-mandatory foreign key relationship (see below). |
 |
|
|
The reference table is missing a value. When referential integrity is enforced,
the database management system raises an error.
To solve, add the missing value to the reference table and enable the foreign key constraint. |
An optional relationship from the perspective of the child (with the "0"
showing on the parent side!) means that the child (fact table or non-reference
table) is not existence dependent on the parent (or reference table). This is
shown in the second and fourth cases above. A mandatory relationship from the
child's perspective (no "0" showing on the parent side) means that
the child is existence-dependent on the parent. This is shown in the first and
third cases above. When the relationship is mandatory, two situations arise:
in addition to being existence-dependent,
the child may be or may not be identification-dependent
on the parent. This is linked to the notion of an identifying
relationship, which does not show in the IE and Barker notations.
Identifying relationships show in the IDEF1X notation as full lines and non-identifying
relationships show as dashed lines. The diagrams in this section do not show
this, so refer to the ERwin section below.
Resolving the non-mandatory foreign key relationship
It is best to resolve non-mandatory foreign key relationships by adding a default
value in the reference/dimension table or by creating a sub-type:
Add a default value such as
"unknown" or "non-existant"
in the reference/fact table and
make the null foreign key point
to the row with the default value. |
 |
Or make a sub-type in which all fields
are mandatory so as to
make the relationship mandatory. |

|
Many to many relationships
| Example |
Notation |
Barker Notation |
Comments |
|
|
|
|
|
 |
|
 |
Resolve many-to-many relationships
by inserting an associative
entity to
describe the relationship.
Make the foreign keys into a primary key
so as to force unicity of the
key combinations.
Needless to say, the foreign keys in the
middle should not be null. |
Note that the foreign key mechanism does not enforce mandatory relationships.
Types of Joins
A theta-join is a join using a comparison between fields of two tables. Theta-joins
include all comparison operators such as > or <. An equi-join refers to the
most common type of theta-join which uses only equality in the condition.
| Relation |
Table |
File |
| Tuple |
Row |
Record |
| Attribute |
Column name |
Field |
| Degree or arity |
Number of columns |
Number of fields |
| Cardinality |
Number of rows |
Number of records |
R = {a1, a2, ..., an} is set of attribute
names for relation schema r(a1, a2, ... , an)
Schema or intension corresponds to instance or extension, which is a set of
n-tuples without duplicates.
Note: tuple rhymes with couple.
The smallest unit of data is a scalar, the values of which are part
of a domain. Determining the domain of a an attribute (field) is an important
step in the analysis. The data type (character or numeric) is often not enough
to define the domain. One way of constraining values to a domain is to define
a reference table. Is NULL or blank part of the domain? What are the maximum
and the minimum values? For dates, are times included? For numbers, are they
integers or decimals? Values are constrained by the DBMS by the data type definition,
by the use of the foreign key mechanism, by constraints on NON NULL values and
other types of constraints depending on the DBMS. These rules are integrity
rules.
A relation on a collection of domains is composed of (see C.J.Date):
- A heading with pairs of attribute names and corresponding domain names:
{(A1, D1), (A2, D2), ..., (An,
Dn)}, with i=1, ..., n.
n is the degree.
- A set of tuples, which are pairs of attribute names and values (from the
corresponding domain of course):
{(Ai1, vali1), (Ai2, vali2), ...,
(Ain, valin)}, with i=1,2,..,m.
m is the cardinality.
| Superkey |
Set of attributes with distinct values; can identify a tuple. |
| Candidate key |
Minimal superkey.
A candidate key has uniqueness property and is irreducible (no subset has
uniqueness property). |
| Primary key |
No null values |
| Foreign key |
References primary key of another table (same domain of values) |
Note that, because by definition relations cannot contain duplicate tuples,
therefore there always exists a candidate key. The primary key is chosen amongst
the candidate keys. (Generally, there is not much of a choice).
Foreign keys:
update option: either cascade (an update on the primary key cascades to matching
foreign keys) or restrict (an update is not possible if matching foreign keys
exist)
delete option: either cascade (delete rows with matching foreign keys) or restrict
(cannot delete if foreign keys exist).
Some DBMS' allow foreign keys to have nulls, others do not.
 |
Total participation: each entity participates
Partial participation: some values are null
 |
Alternative terms
| Table |
Alternative |
| Row |
Record |
| Column |
Field / zone |
| Table |
File |
| Database |
Library |
Some basic issues before the normalization process:
- Verify that each column contains only one fact (no asterisks, etc.)
- Is there a hidden meaning in the sequence or in one of the columns?
- Remove derivable data... but keep note of it. It could be added later in
the physical model for performance reasons, but it has no place in the conceptual
model.
- And, of course, determine the primary keys:
- A primary key is one of the possible candidate keys of a table (ideally
the shortest or the one that best responds to requirements). It can be
a natural identifier or a surrogate key.
- For dependent entity classes, use the foreign key plus another column.
- For tables implementing a many-to-many relationship, use the foreign
keys.
- If a structured primary key can only contain foreign keys as one of
the columns if the foreign key represents a mandatory, non-transferable
relationship.
- The inclusion of foreign keys in a structured (multi-column) primary
key enforces nontransferability.
Functional Dependancies
Functional dependancies are the starting point for denormalization.
A → B if for each item in A, there exists one and
only one possible value in B.
A is generally a key of ID of some sort.
"→" reads "determines" or "is
a determinant of".
Armstrong's axioms:
X and Y are sets of attributes (or columns)
- Y is included in X then X → Y (a subset is functionally
dependant on the superset)
- X → Y then X union Z →
Y union Z
- X → Y and Y → Z then
X → Z (transitivity)
Closure F+ of F is a set of all functiona dependancies implied by F. This means
that a key functionaly determines all attributes. And all attributes of the
key are needed to fully determine all attributes in the relation.
Domain D = {values} (a domain D is a set of values)
Relation is included in D1 X D2 X D3 X ...
X Dn (a relation consists of tuples and each domain corresponds to
a column).
1st Normal Form:
(Student, course1, course2, course3, course4) |
(Student, course1, course_type1)
(Student, course2, course_type2)
(Student, course3, course_type3)
(Student, course4, course_type4) |
An entity is in 1st normal form if there are no repeating groups
of attributes.
Note that a single attribute containing a list also violates the 1st
normal form.
2nd Normal Form:
(Student, course, room, course_result)
course <--
room
room is dependant on only part of the key, i.e. on the course |
(course, room)
(Student, course, result) |
An entity is in 2nd normal form if it is in 1NF and if all the non-key
attributes are fully dependant on the primary key, meaning that the non-key
attributes are dependant on all of the primary key and on none of the subsets
of the primary key. A partial dependancy is when a subset of the primary key
determines one of the non-key attributes.
3rd Normal Form:
(Course, room, building)
room <-- building
Building is dependant on a non-key field, i.e. on the room |
(course, room)
(room, building) |
An entity is in 3rd normal form if it is in 2NF and if every determinant
of a nonkey attribute is a candidate key. Or, no non-key attribute determines
another non-key attribute.
One special case of violations of the 3rd normal form are derived
attributes that can be calculated from another attribute.
A trick to remember is that every attribute is dependant "on key, the
whole key, and nothing but the key".
Boyce Codd Normal Form (BCNF)
A and X are sets of attributes, and A is not in X
If X → A then X must be a candidate key.
That is all columns that determine other columns must be candidate keys.
In other words, every determinant of key items (BCNF) and of nonkey items (see
3NF) must be a candidate key.
Situations where a table is in 3NF but not in BCNF occur when there are overlapping
candidate keys.
Note that BCNF may not preserve dependancies required by the business rules
(that is each dependance can be reconstructed). The tradeoff is that normalization
prevents redundant data. Program logic can be used to enforce additional business
rules.
4th Normal Form
A sort of cartesian product (but not complete) within a key-only table. Make
two relations. But watch because this may not preserve dependancies.
See 5NF because it includes 4NF and that it is easier to understand.
5th Normal Form
4NF and 5NF issues occur in tables whose columns are all part of the primary
key. This means that there must be at least three columns in the key and no
nonkey items. If there are nonkey elements in the table, then the table is in
5th normal form because the related issues do not apply.
According to Chris Date (and Simsion [2]), examples with nonkey items do not
exist in practice.
As suggested by [2], handle 4NF with 5NF together because 5NF includes 4NF
and it is easier to explain. It is explained by saying that "no further
table splits are possible with different primary keys in the resulting tables".
Basically, the normalization process involves various steps of identifying the
need to split tables and assign new primary keys to the resulting tables. A
correct normalization results in tables that can be re-joined so that the original
tables are re-constituted. 5NF says that this process should continue until
one of the two is true:
- Any further splitting leads to tables that cannot be re-joined.
- The only splits left are trivial, meaning that the resulting tables each
have the same primary key.
So, when in doubt, split the tables, with different primary keys in each, and
try to re-constitute the original table.
Note that if the tables are split and each has the same primary key, this could
still be useful if the underlying entities are in fact different but just identified
(temporarily) with the same key. Simsion [2] gives the example of a bin where
one table describes the physical dimensions of the bin and the other describes
the contents.
Domain Key Normal Form (DKNF)
All constraints are a consequence of domains or keys. This means that constaints
should be enforced by keys (see normal forms above) or by limiting the allowable
values (domain). This normal form is not used often. It is noted here just for
information.
Method
- Remove the repeating groups of columns. The result is in 1st
normal form.
- Identify the candidate keys. Choose the primary key.
- Look for partial key functional dependancies. If the key has only one column,
then skip. Remove dependant attributes and create a new relation with the
key and attributes. This gives 2nd normal form.
- Find non-key functional dependancies. Remove dependant attributes and create
a new relation with the key and attributes. This gives 3rd normal
form.
- Look into BCNF when there are overlapping candidate keys
- If the table has non-key columns, then you are done. For key-only tables,
see 4th and 5th normal forms above.
Data Model
High level data model that captures the categories of data and their business
rules. Stick to data that is to be tracked by the IT system.
The starting point is the Business
Process Model. This describes what and how things happen in the business.
It does not describe the data. This is because the users generally see things
from the point of view of the process and not of the data.
The Conceptual
Model refers to a high-level model showing entities and relationships
but few or no attributes. It is useful in scope definition.
See Data Modeling (conceptual model) for more details.
The Business Model describes the data elements from the point of view of the
business users. Some argue that there is only one business model. Linked to this type of model are the
external models, of which several can exist. The conceptual model and the business model
may be the same.
The Logical Data
Model fully implements all requirements. It is in third normal form.
See Data Modeling (logical) for more details.
The DBA implements the Physical
Data Model. It is optimized for performance and therefore takes into
account denormalization for performance purposes, merging of tables, implementation
of sub-types/super-types, partitioning, ...
See Data Modeling (physical) for more details.
The whole diagram is an Entity
Relationship Diagram (ERD).
Keep a central place for general business rules.
Also keep re-occuring definitions such as "Name = first name + last name"
Steps
- Identify the entities
(categories, nouns of the business, "What are the key subjects that the
business deals with?" )
An occurrence
or an instance
is one specific case of an entity.
Use singular nouns for the entities.
- Describe each entity. A good description is as important as choosing an
appropriate name for the entity. Try to make sure that each term is
non-ambiguous and well defined. Also explain differences between synonyms.
However, keep to the level of detail that is pertinent.
Include some business examples.
Additional comments include who "owns"/is responsible for the entity,
source of the definition, last changes, ...
- Build a glossary
of common and important business terms, even if they are not used as entities.
- Simsion [2] suggests developing an Object Class Hierarchy.
Every term given by the business users is noted down as
an object class,
whether it becomes an entity or an attribute. These object classes are then
grouped appropriately by their top-level object classes. The users agree on the top-level classes and
their definitions and eventual sysnonyms, then likewise agree on the object classes at the next level down.
- Define what makes an entity's occurrence unique. Include possible non-unique ways of identifying an occurrence.
- Identify the relationships
(use arrows and verbs). Ideally, each arrow has two verbs. "Are the entities
related in any way?"
- In the discussion on relationships, distinguish between dependent and independent entities.
Dependent entities require other entities to exist:
- Attributes describing details of another entity
- Associations describing the relationship between two other entities
- Categories or sub-types, which can be exclusive or inclusive/overlapping.
- Define the cardinality,
which is the number of occurrences: minimum and maximum nomber for each end
of the relationship. See below.
- Gather other business
rules (cardinality is considered a business rule).
- Assign the attributes
to the entities (specific pieces of information, properties of the entities.
These will be the fields).
Note "(M)" for multiple attributes, like phone numbers.
Stick to high level in describing attributes (such as "address",
"name") and define these in greater detail in a central place if
it is seen as necessary.
Document aliases, data types and lengths, display formats, ranges of acceptable
values, validation rules, computation rules (though don't get involved in
details too soon).
use singular nouns to name the attributes. Some (in particular the methodology document
for ERwin) say to prefix the attributes with the entity name. The author of this page
thinks that systematic prefixing makes the model more difficult to read.
Certainly, prefixing with the
entity name should be done every time there is a possibility of a synonym.
But systematic prefixing is not necessary.
- Note particularities in the domains of the attributes, such as
no negative values, no null values, long strings, particular values, ...
A domain is the full set of possible values.
- Document any rules linked to the attributes (part of the business rules).
- Identify the primary keys
- Identify other (non-unique) keys
- Normalize the model or put into star schema

This diagram shows three entities.
A "has" 0 to many Bs and B is "belongs" to one and only
one A.
B "belongs" to 0 or 1 Cs and C "has" 1 to many Bs. |
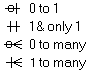 |
See basics of data modeling in Data Modeling
See http://www.agiledata.org/essays/dataModeling101.html
Some comments
In one presentation (sorry, I can't remember who), suggested three contradictory
requirements: design elegance, processing speeed, and information requirements.
I understood this to be similar to the "cheap, good, fast - pick one" dilema.
The conceptual model is based on the analysis of the business processes.
The conceptual model is a high-level overview of the data entities. It supports
discussions during business and systems interviews. Accompanied by a glossary, it provides the
business-related descriptions of the entities, the relationships between these entities, the main attributes,
examples of values, and owners.
Interviews with business users and eventual existing
data models provide the information for building the conceptual model.
Verification of the conceptual model: the stakeholders should verify that:
- All the business requirements are met (completeness). This includes
being able to answer questions that users will ask. List some sample queries.
In data warehouse terms, this includes the measures and the "measured by"
or dimensions.
- Each component is correctly defined;
- No components are not required (all components are necessary).
To verify the model, [2] suggests using the assertions approach,
described below.
Though the primary keys are formally defined in the logical data model,
a clear idea of what constitutes a single row is necessary at this level.
Define what makes an entity's occurrence unique.
Determine the scope[4].
This results in a statement such as "a data model for the accounting department's application
in six months" or "a model of current business processes in the bank."
- Function (rules and language of the "business" side or of the related IT applications)
- Realm (are we modeling just a process, a department, or a whole industry?)
- Time (are we modeling the situation as of now, the near future, or a year from now?)
Steps for High-Level Data Model
Taken from [4].
- Define the purpose, which could be capturing existing or proposed business
or application terminology and rules
- Identify the stakeholders, in particular those who are going to use the
system and those who will be affected by it
- Identify the people who will help in building the model. These people
can suggest documentation.
- Determine the type of model: relational data model, dimensional data model,
business perspective model, or model of an existing application
- Choose where to start: a top-down approach or a bottom-up approach.
A top-down approach starts with input from business actors. A bottom-up
approach starts with the existing systems.
- Create the view for the audience, meaning for the people who will use the
model. Then, adapt the model to the enterprise terminology
- Get approval from the stakeholders
- Market the approved model and maintain it
See also data modeling steps.
At an attribute level, the conceptual model defines the attributes in business
terms and defines any related business rules. On the other hand, compared to
the conceptual mode, the logical model defines the type of data, the constraints
(mandatory, allowed values, ranges), eventual formatting, and the composition
of the primary key. The logical model includes:
- Entities and relationships
- Attributes: data types, mandatory constraints, allowed values, ranges, eventual
formatting
- Primary key for each entity
- Foreign keys
- Resolution of many-to-many relationships
- Third form normalization
- As much detail as possible, but without regard to the possible physical
implementation
The main types of attributes are:
- Identifiers, generally numbers, but not necessarily, often used in primary
keys;
- Categories and flags, to be implemented with a reference table or with a
constrained list of values; nulls should be avoided here and replaced with
a value such as "unknown";
- Quantifiers: a number, location or time. Define the minimum accuracy of
the data;
- Text items, containing descriptive text;
- Dates.
See notes on profiling in Data Quality, element analysis
See also data modeling steps.
The physical model is derived from the logical model in a fairly automatic
way. The main decisions concern performance and implementation of the structures
that have been designed. In particular, decisions have to be taken about indexes,
storage (table space usage, free space, ...), memory, locking strategies, creation
of views, ...
Some decisions also impact the data model:
- Using sets instead of reference tables
- Splitting large tables, either horizontally or vertically
- Merging tables that are often joined in queries
- Duplicating tables into one "active" table and other tables that
contain copies of the data
- Denormalization and aggregates for performance purposes
- For date ranges, or other ranges, record both ends of the range instead
of just one end
- Undo hierarchies and put them into columns of a table
- Implementation of sub-types/super-types
- Partitioning
Physical Database Planning
Verify that the server has enough cpu, memory, disk space. Do the same for the SAN.
disk storage capacity
- data tables and indexes (together on SQL Server)
- transaction logs
- tempdb
- full-text indexes
Disk throughput capacity
- PhysicalDisk: disk read bytes/sec and disk write bytes/sec
- also look at PhysicalDisk: Avg. disk read queue length and Avg. disk write queue length depending on if read or write is more frequent
Databases and locations (in the case of remote locations):
Is some data used only in the remote connections.
CPU performance
- Affinity mask settings: controls swapping of threads between CPUs
- Measurements: find baseline and look for variable such as number of users and/or applications. Then test the assumptions. Then this can be used to forecast future use
- Degradations due possibly linked to compilation of stored procedures and use of cursors.
- Measurements: SQLServer Plan Cache and SQLServer: SQL Statistics (in system monitor)
Measure memory with
- Available MBytes: (should not get near 0)
- Pages/sec: measures swapping of memory page to disk
- Committed Bytes: should stay near 0
- Commit limit: if not 0 then more pageing file space is needed.
- Memory manager: total server memory.
Network
- Identify databases and data consumers on the network diagram
Concentrate on ETL, replication, backups and large queries from client applications.
- Look for low bandwidth connections between the components above.
- Look for firewalls and anti-virus servers on the paths.
- Measure the network interface (bytes totals/sec) and SQL Server (general statstics: user connection)
Regulatory issues
- Longevity of data: data must be kept for several years. This takes up storage
- Privacy --> encryption uses more space.
Data backup and recovery
- Interval (daily, weekly)
- Where is data stored to
- Type (complete, incremental, ...)
- RPO: Recovery Point Objective: how little data can be lost
- RTO: Recovery Time Objective: length of recovery of data
Data archiving
- How often is data needed?
- How fast is it needed
- Options: fast drives, larger slower drives, tapes, etc.
- Archiving helps with problems due to excessively large tables, such as long backup times, long index buiding/rebuilding times and poor query performance
Server Consolidation
- Needs a lot of planning and caution
- What applications will run?
Data Distribution
Main issue is connectivity
Growth
- N = number of periods (month, year)
- Try to figure out what the growth is per month, per year
- Linear growth: future space required = current disk space + (linear disk space growth amount * N)
- Compound growth: future space required = current disk space * (1 + growth percent rate) ^ N
- geometric growth:future space required = current disk space +
initial increment * (1 - incremental growth rate ^ N)
/ (1 - incremental growth rate)
This section describes the steps for going from an enterprise
data model, which is generally fully denormalized, to a
data model appropriate for a data warehouse (see Silverston [5]).
More notes on designing a data warehouse are in
Project Management Notes.
Starting with the normalized enterprise data model, complete with
conceptual and logical models, we take the following steps.
This constitutes the physical model of the data warehouse.
- Remove the operational data and keep only the elements that have a reasonable
chance of being used in the data warehouse
- Add time, in the form of a snapshot date or in the form of "from" and "thru"
timestamps
- Adding derived data that many users need. Typically, this would be a
calculation common to many reports.
- Adding a way to keep history in the relationships, relationship artifacts
according to Silverston [5].
- Create summary tables. This step should show in the logical data model.
Remember that it is easier to create summaries when you have details.
Therefore, when in doubt, prefer keeping details. The best is to have both
summary and detail tables.
- Denormalize by merging tables, especially if the data is generally
inserted at the same time in both tables. An example is header and detail
tables for orders. Or, you could treat the header as the summary table
and add line counts and order totals (see previous step).
- Denormalize by creating arrays or repeating groups of attributes.
The number of repeating groups has to be known.
- Orgnanizing data according to how often it changes. For example,
patient information such as name and data of birth seldom changes,
but the address changes occasionally, and the patient condition may change often.
Note that, according to Silverston [5],
we do not need to model the processes in the context of a data warehouse model.
The enterprise data model gives the structure. Kimball insists
on knowing how the business works. I do not think that means building the
Business Process Model.
Simsion [2] proposes an approach using assertions for verifying the data model
with the users. Ask the users to validate the follwing assertions:
- Basic class: "An <Entity Class name> is <enter definition
of the entity class>."
- Sub-class: "A <sub-class name> is a type of <userclass name>,
namely <definition>."
- Relationship: "Each <entity1> { must | may } <relationship
name> { just one | one or more } (other) <entity 2> that { may |
must not } change over time."
"must | may": optionality of relationship;
"just one | one or more": cardinality;
"other": for recursive relationships, add "other" to make
it more easily readable;
"that { may | must not } change over time": transferable or non-transferable
relationship.
- Additional assertion for optional relationships (to make sure that the users
understand that the relationships is not mandatory):
"Not every <entity1> has to <relationship name> a(n) (other)
<entity2>."
- Single valued attribute: "Each <entity name> { must | may } have
a(n) <attribute name> which is <attribute definition>. No <entity
name> many have more than one <attribute name>."
- Multi-valued attribute: "Each <entity> { must | may } have <attributes
in plural form> which are <attribute definition>. A(n) <entity>
may have more than one <attribute>."
- Addtional assertion to verify an optional attribute: "Note every <entity>
has to have a(n) <attribute>."
- Attribute of a relationship: "Each combination of <entity1> and
<entity2> { must | may } have a(n) <attribute> which is <attribute
definition>. No combination of <entity1> and <entity2> may
have more than one <attribute>."
- Uniqueness of attribute: "No two <entity in plural form> can
have the same <unique attribute>."
- See [2] for more assertions for intersections and constraints.
Once a version of the data model has published, accompany any new version of
the data model with a list of the changes so that it is easier for people to
validate the changes. Or best, produce a list of changes before implementing
them so as to get feedback before messing up the existing model. This includes
[2]:
- New, changed, moved or deleted entities;
- New or deleted relationships, changes in cardinality;
- Changes to attributes;
- Renaming.
Process Model
Check that the data model can hold the data necessary to support each process.
This can be done with a "CRUD" matrix. Done the left side are the
processes, along the top are the entities. In the cells are the indication of
which processes Create, Read, Update or Delete which
entities.
| |
Entity A |
Entity 2 |
Entity AB |
Entity CD |
| Process 1 |
C
|
|
|
R
|
| Process B |
R
|
C
|
U
|
R
|
| Process XYZ |
R
|
|
D
|
C
|
Some reminders:
- Use tab key to navigate between the different parts of the entity
- To create a relationship, click on the appropriate icon, then on the parent,
finally on the child. Tip: the parent corresponds to the top end of the icon,
the child corresponds to the bottom end of the icon.
- In the case of an identifying relationship, the child has rounded corners.
It is a weak entity. The line is full. Dashed lines are non-identifying.
- subtype is the little half circle icon. Click on super-type then sub-type
for the first subtype. For the following subtypes, click first on the half
circle then on the subtypes.
- Key groups allow for alternate keys and inversion keys in addition to primary
keys. Alternate keys are unique keys. Inversion keys are non-unique keys that
will later be translated into indexes to help searches or sorting.
- Go from logical to physical with menu > tools > derive new model.
If the model was created as logical and physical, switch between the two design
layers at the bottom of the menu "model".
- Options for display: menu > format > entity display / relationship
display :
Options for the model as a whole (including switching between IE and IDEF1X):
menu > model > model properties > tab notation.
- So as to prevent the use of homonyms, it is possible to prevent duplicate
names: menu > tools > names > model naming options > tab "duplicate
names". This prevents both duplicate entity names and duplicate attribute
names.
- Perform the actual database generation with menu > tools > Forward
Engineer/Schema Generation.
- The basic aspects of the IDEF1X notation are that the crow's feet are replaced
with a black dot, thus indicating the child entity. The cardinality is indicated
with additional indications ("P", "Z"). Many-to-many relationships
are shown with black dots at either end. In one-to-many relationships, a diamond
indicates that nulls are allowed on the "one" or parent side of
the relationship.
- Erwin automatically puts the foreign keys in the child entity. This is called
migration.
- When two foreign keys have the same name and the same data type, they are
unified,
meaning that they are merged into the same field. Therefore, prefer identifiers
that are more explicite than just "ID", so as not to risk having
two foreign keys merged. Another option is to define rolenames in the relationship
properties. This basically defines the alias underwhich the foreign key will
show in the child entity. In the case of recursive relationships, a rolename
must be defined.
- Define default formatting in menu > format > default font and colors.
Note that at the bottom of the dialog box, there is an option to apply to
new objects or to existing objects. Some settings get applied with a delay,
so change another setting to implement the previous setting!
- Printing: for the scale, either move the lines indicating the pages or choose
the scale below. Choose individual pages with ctrl+click. The icons for the
header and footer are not intuitive. See image further below.
- The naming standards file includes naming standards for the logical and
physical models and includes a glossary. The glossary is one of the tabs accessible
in the naming standards editor.
- Subject areas: create in the "model" tab of the Model Explorer.
Then drag the objects from the "entities" tree node, or open the
properties dialog box for the subject area. The relationships "follow"
the entities. In the dialog box, the icon with the five tables allows moving
an object with its neighbors (but you cannot bring in neighbors, you have
to remove the object then bring it in with its neighbors). All objects are
part of the main subject area. Moving objects in one of the subject areas
does not affect the position in other subject areas.
Suggestion: create subject areas also for each of the views (with keys, just
descriptions, ...). Or use "Stored Displays".
- The Activity Pane at the bottom records all actions. They can be selectively
reversed. To keep a report of all activities during a session, go to menu
> tools > options > general tab > activity summary. To view the
current activity details or summary, go to menu > tools > data browser
(very intuitive!). In fact, the "Report Template Builder" is not
where to build reports.
- Look at the schema (only in physical data model): menu > tools > forward
engineer > schema generation > button "preview". For creating
scripts to alter an existing schema, use menu > tools > alter script/schema
generation. Suggestion: remove the triggers in the "trigger" section
and the "on delete" and "on update" in the referential
integrity section.
- For reverse engineering, use a script that does not have the "if exists
then drop ..." From the result, derive another script, because modifications
can not be easily made. The character set may be of importance too. Copy and
paste script into another text file.
- For report template creation, go to menu > tools > report template
builder > report builder. Pull the elements to the right pane. Right-click
on each element and modify the properties.
- There is a difference between linking to a source model and adding a source
model. Linking to a source model does not bring in new objects. However, selective
synchronization is possible.
- Transforms: choose a relationship and the appropriate icons will show in
the "transforms" toolbar. A wizard allows the choice of some options.
The resulting transforms are listed in the object explorer. Source objects
are visible by rigth-clicking the transform in the object explorer and choosing
"display source objects" or by changing the overall display in the
edit menu or with the icon in the transform toolbar.
- Reverse a transform: deletes the transform and leaves the source objects.
- Resolve a transform: deletes the transform and leaves the target objects.
- Remember to add a rolename for the recursive relationships. Otherwise, the
table will point to itself with the same field as the parent and child key.
Relationship Types
Identifying relationships: the child depends on the parent for identification
(and existence as a consequence). The child is identification-dependent.
(Notice how the foreign key is put automatically into the primary key of the
child).
Strictly speaking, the notion of dependant and independant entities is not part
of the IE notation but ERwin includes it anyway.

Non-identifying relationships: the child does not depend on the parent for
identification. However, it may depend on the parent for existence and in this
case, nulls are not allowed on the parent side (see further below).
(notice how the foreign key is put automatically added to the child, as a non-key
column.
Also note that the line is dashed.)

Cardinalities for one-to-many relationships
The left-most column shows the additional indications ("P", "Z",
"3") when the "format > relationship display > cardinality"
option is chosen in the IE notation.
(The parent is on the right side, the child on the left).

For non-identifying relationships, the parent side can be null too. If the
child is existence-dependent on the parent, then no nulls are allowed in the
foreign key attribute of the child. Otherwise, nulls are allowed.
(The parent is on the right side, the child on the left)

Many to many relationships are shown as follows. Note that few options are
possible in the relationship properties.

The notation for super types and sub types is as follows. The discriminator
is shown next to the symbol. Exclusive/complete sub-typing is shown below. An
inclusive sub-type relationship is without the X in the IE notation (the term
is not used in IDEF1X). An incomplete relationship is shown with a single horizontal
line with the IDEF1X notation (complete and incomplete relationships are not
noted in the IE notation). The terms "inclusive" and "exclusive"
are part of the IE notation. "Complete" and "incomplete"
are part of the IDEF1X notation. Because the sub-types are weak entities, the
boxes are rounded in IDEF1X notation.

Below are the (non-intuitive) icons for building the header and footer on the
printed page (and no tooltip appears when hovering over the icon):

Referential Integrity options:
- Cascade: if a parent is deleted, the child is deleted too. Useful in some
cases of many-to-many relationships. Otherwise, it is a dangerous option.
- Restrict: deleting in the child and/or the parent entity is restricted if
there is a relationship between the two. This is the "normal" foreign
key constraint behavior.
- Set null: when a row in the parent entity is deleted, the foreign keys in
the child entity are set to null. This is "softer" than cascade.
- Set default: when a row in the parent entity is deleted, the foreign keys
in the child entity are set to the default value. This is similar to the "set
null" option.
- None: no referential integrity rules.
Reports
Some starting suggestions. Use in the report builder (menu > tools >
Report Template Builder > Report Builder) and create a new template.
- Best is probably HTML (for starts) because it handles the long texts better
than PDF.
- Two sections of the same type can be added to a report.
- In the document properties, tab "Export", set the "HTML Export
properties" to "Picture Report as Links" so that there is no
warning about active scripts when opening the page with the picture.
- Picture section: just choose one of the picture types. The additional information
selected in this section is visible by clicking on the related entities of
the picture.
- First entity section: select the entity name and the "Parent to Child"
and "Child to Parent" rules for both the parent and child relationship
tables. This shows the rule in the form "An account has zero, one or
more financial_transactions".
- In relationships, the type is "(non-)identifying", "sub-category".
- In entities, the type is "dependant", ....
- In HTML, "hierarchical" section layout is generally more readable
than "tabular".
- Second entity section: select the name and definitions of the entities.
Add information about the attributes and domains.
- For the physical model, the "generate" column is probably not
necessary. Put the create statement of tables in one "table" section
and the other information in another "table" section. Generally,
the table creation script also includes the creation of the indexes and constraints.
If so, then there is no need to select the creation scripts in the detailed
report of the tables.
fundamental entities: is this the equivalent of independant entity???
Methodology
The proposed methodology is:
- Build the Entity Relationship Diagram (ERD), which contains entities
and relationships, but few attributes and probably no keys. Many-to-many relationships
are not resolved. The ERD covers the whole enterprise or a large area.
- Based on the ERD, go into more detail with the Key-based model, in
which the primary keys are added. The big effort here is identifying the primary
keys correctly.
- Fully-attributed model: entities with their attributes and all relationships.
Because there is a lot of detail, this diagram is restricted to the project.
Though there is a lot of detail, this is considered a logical model in the
ERwin terminology.
- Transformation model: contains all details of the physical model
that DBAs and developers can use.
- DBMS model: the implemented model.
Tutorials:
- [1] Reingruber, Michael C. and Gregory, William W.: The Data Modeling Handbook,
a best-practive approach to building quality data models, 1994, John Wiley
and Sons
- [2] Simsion, Graeme C.; Witt, Graham C.: Data Modeling Essentials, Third
Edition, 2005, Elsevier
- [3] Date, Chris J.: An Introduction to Database Systems, Addison-Wesley,
1995
- [4] Hoberman, Steve: "Creating
a Successful High-Level Data Model", a condensed excerpt from the authors
Data Modeling for the Business (2009, Technics Publications),
by Steve Hoberman, Donna Burbank, and Chris Bradley
- [5] Silverston, Len: The Data Model Resource Book, Volume 1,
A Library of Universal Data Models for All Enterprises,
2001, Wiley
- [6] Hoberman, Steve: Data Modeling Made Simple,
A Prictical Guide for Business & Information Technology Professionals
2005, Technics Publications















