SQL ServerThese are my personal notes that I use as a quick help in my work.
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||
| master | system area |
| model | templates |
| msdb | used by ms-sql agent |
| northwind pubs |
examples |
| tempdb | temporary storage |
Query analyzer is equivalent to SQL*plus
The Enterprise Manager can view all servers
Create a new db:
Create a new user: create "Login". For properties, right-click the user then properties > user mapping. Select the database. Then, for that database, grant "public" and eventually "db_owner" roles.
Backup a database:
Note that when deleting databases, the files automatically are removed from the file system, yet the database have to manually removed from the database maintenance.
When the log file has grown so much that the disk is full, the log file must be truncated:
BACKUP LOG Database_name WITH TRUNCATE_ONLYBACKUP LOG Database_name WITH NO_LOG -- (TRUNCATE_ONLY
and NO_LOG are synonyms) TRUNCATEONLY
is used): DBCC SHRINKFILE (N'databasename_log' , 0, TRUNCATEONLY)Transaction logs fill up until they are backed up. But warning: you cannot back up a transaction log that is completely full because some space is needed to record the backup. It will be necessary to truncate the log before backing up. Then back up the whole database... of course.
Types of backup
Suggestion: Full once a day, transaction backup several times an hour, differential a few times a day.
Recovery modes:
Implement with:
Restoring:
RESTORE HEADERONLY FROM DISK = 'C:\SQL\Backup\North.bak'
RESTORE FILELISTONLY FROM DISK = 'C:\SQL\Backup\North.bak'RESTORE DATABASE Northwind FROM DISK = N'\\TestServer\G$\Tran.BAK' WITH FILE = 4RESTORE DATABASE Northwind WITH RECOVERY --
Resets the status of the database so that users can access it.
No additional restores can be issued after this command is executed.RESTORE VERIFYONLY -- see integrity of the backup files (best to run after backup) RESTORE DATABASE NORTH
FROM DISK = 'C:\SQL\Backup\North.bak'
WITH MOVE 'NORTH_Data' TO 'D:\SQL\Data\North_Data.mdf',
MOVE 'NORTH_Log' TO 'E:\SQL\Log\North_Log.ldf'See also:
SQL Server 2005 services
SQL Server 2005 architecture:
Web applications use http. A web browser (html) connects to the web server. A web service needs a web service client and uses SOAP/XML over http. Now, SQL Server can be a web server, but only for SOAP
The "Surface Area Configuration" is the tool to enable/disable the various features of SQL Server. In particular:
The basic unit of data storage is a page of 8KB. Each page contains a 96-byte header with system information, including page number, type, free space. Page types include data, index entries, text/image (large objects), allocation/free space pages. Row offsets are stored at the end of the page. Large rows cannot span pages, but parts of row can be stored in other pages (row overflow).
Pages are grouped into extents of 8 continguous pages (64KB). Extents can be associated with one object or can be mixed.
SQL injection:
See, among others, http://www.unixwiz.net/techtips/sql-injection.html and http://www.owasp.org/index.php/OWASP_Guide_Project
Best Practices
Auditing:
create trigger ... on database for drop_table, alter_table as begin .. endcreate trigger ... on all server for ddl_login_events as ...Advantages:
Disadvantages
Use SQL files (like Oracle)
to run, open in SQL Query Analyzer
add comments: ctrl+shift+C
remove cmts: ctrl+shift+R
upper case / lower case: ctrl+shift+U or L
bookmark: add with ^F2, remove with ^shift+F2, navigate with F2 or shift+F2
SP_WHO2: see current processes
If needed, change the configuration parameters (set the value, then apply the value):
sp_configure 'option_name', value
GO
RECONFIGURE | RECONFIGURE WITH OVERRIDE
GO
Enterprise manager: Define the connection username and password : edit sql registration properties.
use database
Define the default database for the queries. Or, in query analyzer, use the
drop-down list.
SET ANSI_NULLS = ON |
NULL = something --> NULL |
SET ANSI_NULLS = OFF |
NULL = NULL --> true |
| Oracle | SQL Server |
| schema and tablespace | database |
| data file | data file |
| tablespace | filegroup |
| segment | heap/index |
| extent | extent |
| DB blocks | pages |
| System tablespace + control file | master database |
| Rollback segments and redo logs | transaction log |
| temp tablespace | tempdb database |
| data dictionary | System Catalog (resides in part in system database and in part in individual databases) |
| alert log file | error logs (6 by default). Can be viewed with notepad. |
| startup normal | start database system |
| startup restrict | alter database restricted_user |
| alter database open read only | alter database read_only |
| alter tablespace off/online | alter database off/online |
Instead of multiplexing the control and redo logs, use striped and mirrored devices (RAID 0+1) for the transaction logs.
Note that multiple installations are possible. But the fullowing must be managed: installation directory, service name for the SQLServerAgent, main registry hive, default TCP/IP port, named pipe addresses and performance counters. But some things can only exist once on a server, in particular the full-text search service.
To check the rights that I have with my SQL Server user account, use XP_CMDSHELL:
xp_cmdshell 'dir \\theserveer\theShare'
Installation options:
The database files:
Database maintenance: exec sp_helpdb [[@dbname = ] 'database_name'].
Use sqlmaint.exe to run administrative commands.
Memory management is done automatically. But can be configured at server level and at database level. SQL Server tries to use the maximum amount of memory possible without swapping. See SQL Server's Performance Monitor utility for memory management.
Process management: At startup, executables create a process, which in turn spawns threads. Threads have the advantagle of being able to share memory space. In some cases, fibers can be used. Fibers are lightweight threads.
Space management: Increase file size by script, manually in Enterprise Manager or by setting an automatic increase in size. Shrinking is possible. But auto-shrink should be used with caution. Removing a database file is possible, but first remove all objects.
System stored procedures:
sp_helpsortsp_whoexec sp_locksysprocessessysprocesses.lastwaittypesp_help table namesp_helptext view or stored proceduresp_dependsexec sp_createstatsUPDATE STATISTICS table_name | view_name [index_name | statistics_name] exec sp_helpindex [@objname = ] 'table_name' sp_change_users_login @Action='Report';sp_change_users_login @Action='update_one', @UserNamePattern='<database_user>',
@LoginName='<login_name>';USE master
GO
sp_password @old=NULL, @new='password', @loginame='<login_name>'
SQL Server 2005:
By default, the server is closed to remote connections. To open, use start menu > "configuration tools" >
"SQL Server Surface Area Configuration"
Open the database engine to both named pipes and TCP/IP connections.
Then restart (only) the database engine service.
Default file structure:
Location: \Program Files\Microsoft SQL Server\Mssql$instance1
Sub-directories at this location:
BackupBinnDataFtdataInstallJobsLogRepldataUpgrade
Performance tool in windows
64 bit allows
Number of CPUs is determined by
So, dual-core and hyperthreading: like four CPUs
PowerPath: allows a "fail-over" within one node of a cluster from one I/O device to another. Basically for SAN storage. Assumes 2 or more network cards (and even 2 or more connection addresses to target). When the connection fails, then the PowerPath goes through another network card or another connection to the target.
Note that there are no active-active SQL Server clusters. MS clusters assume active-passive only.
EMC storage: Disks grouped into LUNs (Logical units) The LUNs are mapped by the host into the disks.
Network traffic consumers:
Non-paged pool: files that cannot be swapped out. Used for kernel files.
one instance: the number of connections will be more of a problem Several instances on one machine: the sum of maximum memory of the instances must < memory available
On a 32bit cpu, to make available 5 GB of memory to the first instance, you must set the /3GB and /PAE switches in the boot.ini file and change the SQL Server instance configuration to allow AWE.
Data movement options:
BEGIN DISTRIBUTED TRAN
UPDATE ...
END DISTRIBUTED TRANReplication:
Log shipping:
Standby databases
extents are 64K, with 8 pages of size 8K
character data cannot span pages, therefore maximum length is 8K. SQL Server 2005
allows to go beyond by implementing another structure.
Compatibility level is 9.0 for SQL Server 2005.
Following are some tips for upgrading to SQL Server 2005.
sp_fulltext_service 'load_os_resources', 1Tips
Upgrade SQL Server database engine (see also http://msdn2.microsoft.com/en-us/library/ms144267.aspx):
Checklist for (any) upgrade:
Some comments resulting from an upgrade of the i... server:
sp_change_users_login @Action='Report';"sp_change_users_login @Action='update_one', @UserNamePattern='...', @LoginName='...';Resources:
set rowcount 0100
????????????
SELECT TOP n [PERCENT] [WITH TIES] columnA ..... --> show first
n rows, rows tied with last row are included if option is specified
ORDER BY columnB;
Aggregate functions: AVG, COUNT (values in expression), COUNT(*) selected rows / only function to return 0 if no rows / not affected by NULLs , MAX, MIN, SUM, STDEV (st dev for all values), STDEVP (st dev for the population ??ques??), VAR, VARP(??ques??)
SELECT ...
GROUP BY .. ORDER BY ..
COMPUTE { AVG, COUNT, MAX, MIN, SUM , (and others???) } [BY expr] (??ques??)
SELECTshow all rows with null values, even if WHERE clause
not satisfied (??ques??)
GROUP BY ALL -->
useless
a HAVING clause is specified on that column
SELECT ... col, GROUPING(col_name), --> Shows additional lines
with summaries. Null values in result or a "1" in GROUPING column indicate the
level of summaries. GROUP BY ALL option not possible.
GROUP BY ...
ROLLUP
SELECT ... col, GROUPING(col_name), --> Shows additional
lines with summaries of column values (2**n additional lines, where n is the
number of columns). Null values in result or a "1" in GROUPING column indicate
summarized data. GROUP BY ALL option not possible.
GROUP BY ...
CUBE
SELECT ... --> SUM at end of result set
ORDER BY ...
COMPUTE SUM(col)
COMPUTE { AVG, COUNT, MAX, MIN, SUM , (and others) } (one-of-the-columns)
[BY column-list]
Note that the column list must start with the same columns as in the ORDER BY
list, and be in the same sequence
Example compute sum(sum(expr)) where sum(expr) is in the select
clause.
SELECT ...--> SUM for each value of sort_col
(same order of columns as specified in ORDER BY)
ORDER BY sort_col
COMPUTE SUM(colA) BY sort_col
SELECT columns
INTO new_table
SELECT (cartesian prod)
FROM table1 join-type JOIN table2 ON cond [INNER] JOIN, LEFT|RIGHT|FULL
[OUTER] JOIN, CROSS JOIN
Subqueries:
select ... from ...
UNION [ALL]
select ... from ...;
select ... from ...equivalent to MINUS
EXCEPT --
select ... from ...;
select ... from ...
INTERSECT
select ... from ...;
SELECT IDENTITYCOL --> ?
, ROWGUIDCOL --> ?
FROM ...
WHERE expr { = | <> | > | >= | < | <= } expr
str_expr [NOT] LIKE str_expr
ESCAPE 'escape_char'
% 0 or more chars
_ a single char
[] a single char in a range
[^] single char not in range
.. [NOT] BETWEEN .. AND .. (including
end values)
.. IS [NOT] NULL
CONTAINS ( column or * , 'search
condition')
FREETEXT ( column or * , 'free
text string')
.. [NOT] IN (subquery)
.. [NOT] IN (expr, expr, ...) --
treated the same way as OR
expr { = | <> | > | >= | < |
<= } {ALL | SOME | ANY} (subquery)
EXISTS (subquery)
Checksum:
CHECKSUM ( * | expression [ ,...n ] ) --> int
BINARY_CHECKSUM ( * | expression [ ,...n ] )
Noncomparable data types are text, ntext, image, and cursor, as well as
sql_variant with any of the above types as its base type. NULLs have a representation.
Checksum and binary_checksum differ for string values where locale influences
how strings are compared.p
CHECKSUM_AGG ( [ ALL | DISTINCT ] expression )
ALL is the default, DISTINCT returns checksum of unique values. If one of
the values in the expression list changes, the checksum of the list also usually
changes. However, there is a small chance that the checksum will not change.
Examples:
SELECT CHECKSUM_AGG(BINARY_CHECKSUM(*)) FROM Products
SELECT CHECKSUM_AGG(CAST(UnitsInStock AS int)) FROM Products
INSERT [INTO] tablename [(columns)] VALUES (...) --> insert into new tables
INSERT tablename SELECT ... FROM
...
SELECT ... INTO temp_table FROM ...
#temporary local table, valid for session
##temporary global table, valid for session until the last T-SQL statement completes
The default mode is autocommit
Implicit (needs an API to set it): transaction starts at next statement (??ques??)
Pick up the key of a row that was just inserted:
insert ....
select @theLogID = cast(IDENT_CURRENT('LoadingLog')AS INT)
DELETE [FROM] tableA [FROM table_for_joining INNER JOIN tableA ON ...
] ... -- this is not logged
TRUNCATE TABLE tablename
UPDATE table_to_update Rows are updated only once.
SET col = { expr | DEFAULT | NULL }
, @var= expr
, col = tableOther.col
[ FROM table_to_update INNER JOIN tableOther ON table_to_update.key
= tableOther.key
WHERE cond
SQL Server 2005:
By default, the server is closed to remote connections. To open, use start menu > "configuration tools" >
"SQL Server Surface Area Configuration"
Open the database engine to both named pipes and TCP/IP connections.
Then restart (only) the database engine service.
TRY...CATCH uses error functions to capture error information.
ERROR_NUMBER()ERROR_MESSAGE()ERROR_SEVERITY()ERROR_STATE() returns the error state number.ERROR_LINE() returns the line number inside the routine that caused the error.ERROR_PROCEDURE() returns the name of the stored procedure or trigger where the error occurred.RAISERROR (N'text....',
10, -- Severity. 1 to 19, int
1); -- state, int
raiserror in the try part with severity 11 to 19 provokes a catch.
RAISERROR ('Member ''%s'', ''%s'' does not exist', 16, 1, @FirstName, @LastName)
select ... , rank() over ([partition by ..] order by ... desc)
Other ranking functions: row_number, dense_rank, ntile(int) where the int is size of the grouping.
When using CTE, define it with two table definitions joined by a "UNION ALL":
The first table is the anchor. No reference to the CTE. It corresponds to the start of the hierarchy.
UNION ALL
select the children of previous. Navigate using a reference to the start, using the name of the CTE.
WITH cte_name ( col1, col2, col_level )-- do not mention cte_name
AS
(select x, y, the_level
from
where y is null -- assuming that this defines the starting points
UNION ALLUse the CTE immediately after the definition above:
select xx, yy, cte_name.the_level + 1
from a join cte_name on a.y = cte_name.y)
--
select * from cte_name;
CHECKSUM('a string')CHECKSUM ( * | expression [ ,...n ] ) --> int BINARY_CHECKSUM ( * | expression [ ,...n ] ) CHECKSUM_AGG ( [ ALL | DISTINCT ] expression ) Examples:
select primarykey,CHECKSUM_AGG(BINARY_CHECKSUM(col1,col2,...,colN)) from tablename group by primarykey
SELECT CHECKSUM_AGG(BINARY_CHECKSUM(*)) FROM Products
SELECT CHECKSUM_AGG(CAST(UnitsInStock AS int)) FROM Products
BEGIN TRANSACTION -- this is the explicit mode
IF @@ERROR <> 0
BEGIN
RAISERROR ('....', 16, -1)
ROLLBACK TRANSACTION
END
COMMIT TRANSACTION
BEGIN TRY
BEGIN TRANSACTION
....
COMMIT
END TRY
BEGIN CATCH
If @@TranCount > 0 ROLLBACK
raiserror (..)
END CATCH
READ UNCOMMITTED
READ COMMITTED
READ_COMMITTED_SNAPSHOT is set to OFF, shared locks prevent other transactions
from modifying the data.READ_COMMITTED_SNAPSHOT is set to ON, updates by other transactions are possible
and row versioning is used to determine consistent data that is returned to this transaction.
Updates possible, but take care that someone else has not updated the data.REPEATABLE READ
READ COMMITTED.SNAPSHOT
ALLOW_SNAPSHOT_ISOLATION database option to be set to ON.SERIALIZABLE
Concurrency control
Set isolation level with:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ
Note that the isolation level is set for the whole session!, and will continue for the rest of the session. If isolation level is set within a stored procedure, the level will revert to the previous value when exiting the stored procedure.
See isolation level with: DBCC USEROPTIONS
Note that hints may modify the behavior for a single query.
@@TRANCOUNT. If @@TRANCOUNT=0, then not in a transaction.
-- comment
/* ...multiple line */
names: alphabetic letters, _, @, #, numerals
@local_variable
#temporary_table
##global_object
[Bracketed identifiers]
"Quoted identifiers" (only if QUOTED_IDENTIFIER is on)
DECLARE @a_var type --> displays the value
, @another_var type
SET @a_var = ...
SELECT @a_var = column_name FROM .....;
SELECT @a_var AS display_name
SET DATEFORMAT dmy --> sets the default display for datetime
data to dmy.
system variables:
update ...
if @@rowcount=0 print 'no rows updated' DECLARE @DBID INT;
SET @DBID = DB_ID();
DECLARE @DBNAME NVARCHAR(128);
SET @DBNAME = DB_NAME();
- modulo %
- concat +
Precedence:
()
* / %
- +
+ (concat)
NOT
AND
OR
Non-unicode uses code pages, but an appropriate code page does not always exist for a given character. So, better to use unicode.
If a database is unicode, but the ODBC is not (version 2.6 and earlier), then there is an implicit conversion to code pages. This leads to a possible corruption of data if the appropriate code page does not exist.
Use CONVERT() and CAST() to convert between unicode and non-unicode
Use UNICODE() and NCHAR() instead of ASCII and CHAR
Prefix Unicode character string constants with the letter N: N'a string'
CONVERT (target-type, date or string, style)CONVERT(VARCHAR(15), getdate(), n) with n=102, 111, 113CONVERT ( type, GETDATE(), n)CONVERT(VARCHAR(30), getdate(), n) with n=102, 111, 113isnull(a.eclipseEndDate, getdate())user_name() app_name()round(n, m[, t]) len(string)substring(string, start, len), left(string, 4), right(string, 4)CHARINDEX ( 'a char sequence' , column or text containing the sequence
[ , start_location ] ) REPLACE(REPLACE('line1[CR-LF]line2' , char(13),' '),char(10),' '):removes end-of-line characters
CASE epxression WHEN expression THEN result
,WHEN expression THEN result
ELSE
result
END
Case WHEN a_field is not null and rtrim(a_field) <> ''
THEN
Case When cond
THEN value
ELSE value
End
Else 'UNKNOWN'
END
GetDate() Datepart(d, GetDate())convert(date, GetDate())DATEADD(date part, n, date) DATEADD(d, -2, GetDate())DATEADD(d, -2, convert(date, GetDate()))DATEADD(hour, -1, GetDate())DATEDIFF(date part, date1, date2) DATEADD SELECT DATEDIFF(s, '1970-01-01 00:00:00', GETUTCDATE())CONVERT ( data_type [ ( length ) ] , expression [ , style ] ) example:
select CONVERT ( varchar , getdate() , 105 ) -->
string mmm dd yyyy
example: select CONVERT ( datetime , '2005-08-04 00:00:00' , 120 )
--> a date
Note select CONVERT ( varchar , '2005-08-64 00:00:00' , 120 ) -->
string, but watch out, because it is string to string with no validation
Style |
Input/Output |
100 |
mon dd yyyy hh:miAM |
101 |
mm/dd/yyyy |
102 |
yyyy.mm.dd |
103 |
dd/mm/yyyy |
104 |
dd.mm.yyyy |
105 |
dd-mm-yyyy |
106 |
dd mon yyyy |
107 |
Mon dd, yyyy |
108 |
hh:mm:ss |
109 |
mon dd yyyy hh:mi:ss:mmmAM |
110 |
mm-dd-yyyy |
111 |
yyyy/mm/dd |
112 |
yyyymmdd |
113 |
dd mon yyyy hh:mm:ss:mmm |
114 |
hh:mi:ss:mmm |
120 |
yyyy-mm-dd hh:mi:ss |
121 |
yyyy-mm-dd hh:mi:ss.mmm |
126 |
yyyy-mm-dd Thh:mm:ss:mmm (ISO8601, XML) |
130 |
dd mon yyyy hh:mi:ss:mmmAM |
131 |
dd/mm/yyyy hh:mi:ss:mmmAM |
DATEPART ( datepart , date ) with datepart = (without quotes)
yy, yyyy or qq, q or mm, m or dy, y or dd, d or wk, ww or dw or hh or mi, n
or ss, s or ms
DAY, MONTH, and YEAR functions are synonyms for DATEPART(dd, date), DATEPART(mm, date), and DATEPART(yy, date),
remove seconds: CAST(getdate() AS smalldatetime)
see help page "CAST and CONVERT" for details
use db
declare @dbname varchar(30), @table_name varchar(30)
set @dbname = '...'
set @table_name = '...'
execute (' use ' + @dbname @ ' select * from ' + @table_name)
GO
if (exists(select * from information_schema.tables where dbo.table_name
= 'the_table'))
drop table dbo.the_table;
CREATE TABLE dbo.the_table
(theID identity (2, 1) -- start at 2, increment by 1
is_red int check (is_red in (0,1) )
TestDate datetime Default Getdate(),
CONSTRAINT pk_the_table PRIMARY KEY CLUSTERED (theID)
)
CREATE TABLE dbo.detail_table
(
, theID int CONSTRAINT fk_the_table FOREIGN KEY REFERENCES
dbo.the_table (theID)
);
Create table from another: SELECT ... INTO table_name
(equivalent to "CREATE TABLE AS SELECT" in Oracle)
Alter table:
ALTER TABLE table_name add the_column char(1)ALTER TABLE table_name ALTER COLUMN col new_properties -- modify column ALTER TABLE table_name WITH NOCHECK ADD
CONSTRAINT constraint_name_CurrentKeyInd DEFAULT ('N') FOR the_column CREATE INDEX [Idx_indexname] ON [dbo].[table_name] ([the_column])sp_rename 'table.old_name', 'new column name', 'COLUMN' -- rename columnALTER TABLE table_name DROP COLUMN column_nameA covering index is an index that has all the columns retrieved for a query. In this case, the data pages are not accessed. It is faster because there is more data in a page, and therefore there are fewer pages to retrieve. Remember that non-clustered indexes have the indexed field and the clustered field. Use covering indexes as a sort of materialized view.
Non-clustered index: pointers to the data where it is.
Clustered index helps where the retrieval is done on a range, for which output is sorted or on which results are aggregated. Cluster the index on the field that is retrieved by ranges. Warning: clustered intexes need more maintenance on inserts. Look at fill factor Note that non-clustered indexes in a clustered tables uses the full value of the field as the pointer! So cluster on a small field! Non-clustered indexes in a non-clustered table store row pointers with the indexed field.
cluster on the sort column: improvement shows. Not enough to offset the drawbacks.
Index with included columns (create nonclustered index ... on ... include (columns, ..);)
allows an index to "cover" the needs for a query.
Notion of density. For MS, high density is where you have many rows with few distinct values in the index. Highest density: for 10 ajdacent rows, all have same value. Intuitively, high density is where you have many distinct values in the index. Highest density: for 10 adjacent rows, all have distinct values.
In heap, when a line is modified and does not fit, then it is inserted elsewhere and the old location has a "forwarding address". This is a forwarding pointer.
list the indexes:
print 'Indexes'
SELECT object_name(i.object_id) AS TableName,
i.name AS IndexName,
c.name AS ColumnName,
CASE ic.is_descending_key
WHEN 1 THEN 'DESC'
ELSE 'ASC'
END AS ColumnSort
,i.type_desc -- also use i.type
, case i.is_unique when 1 then 'UK' else ' ' end is_unique
, case i.is_primary_key when 1 then 'PK' else ' ' end is_primary_key
, case i.is_unique_constraint when 1 then 'U constr' else ' ' end is_unique_constraint
FROM sys.indexes i
JOIN sys.index_columns ic ON i.object_id = ic.object_id
AND i.index_id = ic.index_id
JOIN sys.columns c ON ic.object_id = c.object_id
AND ic.column_id = c.column_id
and object_name(i.object_id) not like 'sys%'
ORDER BY TableName, IndexName, ic.key_ordinal
SQL Server indexes:
data page size: 8KB, in groups of 8 pages called extents
Index organized table: Use "CLUSTERED" keyword in the column definition.
Temporary table:
CREATE TABLE #table_name ...
CREATE TABLE ##table_name ...
SQL Server also has a type of column "computed column". The value is not physically stored.
Indexes:
CREATE [UNIQUE] [NONCLUSTERED] INDEX index_name ON table_name (column_name, ... )
FILLFACTOR is equivalent to Oracle PCTFREE (FILLFACTOR 90 = PCTFREE 10)
Rebuild:
DBCC INDEXDEFRAG (database name, table name, index_name) : can be done on-line, without stopping queries.
or
DBCC DBREINDEX ( [dbname.owner.]table, { index_name | '' }, fillfactor) : rebuild indexes, but with locks. Fillfactor = 80 for example.
or
CREATE INDEX.WITH drop_existing
Drop index: DROP INDEX index_name
Triggers exist in SQL Server too. Syntax is slightly different. See doc.
exec sp_helptrigger [@tabname = ] 'table_name'
exec sp_helptext [@objname = ] 'trigger_name'
CREATE TABLE t (c VARCHAR(10) [CONSTRAINT constraint_name] NOT NULL -- generally, the NOT NULL constraint is not named NOT NULL if no NULL constraint is specified.col_name the_type NOT NULL CONSTRAINT col_name IN ('val1', 'val2', 'val3'), ...col1 VARCHAR2(6) NOT NULL,
col2 VARCHAR2(6) NOT NULL,
...,
CONSTRAINT constraint_name CHECK ((col1, col2) IN (('aa','bb'),('cc','dd')) -- must be a boolean valueCONSTRAINT constraint_name_uk UNIQUE NONCLUSTERED (column_name)CONSTRAINT constraint_name_pk PRIMARY KEY CLUSTERED (column_name) ON {filegroup_name | DEFAULT}exec sp_helpconstrain
select tab.TABLE_CATALOG, tab.TABLE_SCHEMA, tab.TABLE_NAME, tab.TABLE_TYPE -- only objects for which user has permission are visible
from INFORMATION_SCHEMA.TABLES tab
order by tab.table_type;
select a1 from ( select 'print '''+ table_name +':''' as a1, table_name as a2, 1 as a3 from information_schema.tables where table_name like 'WEBH%' union all select 'select '''+ table_name +''', count(*) from ' + table_name + ';' as a1 , table_name as a2, 2 as a3 from information_schema.tables where table_name like 'WEBH%' union all select 'select top 10 * from ' + table_name + ';' as a1 , table_name as a2, 3 as a3 from information_schema.tables where table_name like 'WEBH%' ) a order by a2, a3;
SELECT COLUMN_NAME
FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE
JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS
ON INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE.CONSTRAINT_NAME = INFORMATION_SCHEMA.TABLE_CONSTRAINTS.CONSTRAINT_NAME
WHERE INFORMATION_SCHEMA.TABLE_CONSTRAINTS.TABLE_NAME = 'the table' AND CONSTRAINT_TYPE = 'PRIMARY KEY'
SELECT fkey.Table_name, fkey.Column_name
FROM INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE rkey JOIN
Information_schema.REFERENTIAL_CONSTRAINTS Ref on rkey.CONSTRAINT_NAME = Ref.Unique_Constraint_Name
JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE fkey ON Ref.CONSTRAINT_NAME = fkey.CONSTRAINT_NAME
WHERE rkey.Table_Name = 'Users'
-- Create a hash index.
ALTER TABLE xyz ADD cs_Pname AS checksum(ProductName) -- create the column as
a function
CREATE INDEX Pname_index ON Products (cs_Pname) -- add the index
Create a trigger:
CREATE TRIGGER [ schema_name.]trigger_name ON { table | view }
{ FOR | AFTER | INSTEAD OF }
{ [ INSERT ] [ , ] [ UPDATE ] [ , ] [ DELETE ] }
[ NOT FOR REPLICATION ]
AS sql_statement [ ; ]
Enable or disable a constraint:
ALTER Table theTable CHECK CONSTRAINT ALL
ALTER Table theTable NOCHECK CONSTRAINT ALL
Data abstraction
Data abstraction consists of using views and stored procedures so as to create a layer around the tables.
Generalization
newID generates only a new UniqueIdentifier
int field can have identity property on it, with a seed value.
CREATE VIEW ... AS
SELECT ...
GO
Cannot use COMPUTE, COMPUTE BY, ORDER BY (except with TOP), INTO
View source of view: exec sp_helptext view_name
Triggers linked to tables or not. Part of the transaction that fired the trigger.
CREATE PROCEDURE procname AS
...
CREATE FUNCTION owner.function_name
( [ @param type [=default] [, ...] ] )
RETURNS type
[WITH function_option]
AS BEGIN
...
RETURN ...
END
Latches are simpler than locks. They are held for much shorter periods.
if condition
begin
..
end
else
begin
..
end
Cursor:
CREATE PROCEDURE proc_name AS
Declare @Temp_Total numeric
Declare @Total_Premium numeric
select @temp_total = 0
select @total_premium = 0
Declare c1 cursor scroll for
select ....
open c1
fetch next from c1 into @Temp_Total
while @@fetch_status = 0
begin
Set @Total_Premium = @Temp_Total + @Total_Premium
fetch next from c1 into @Temp_Total;
end
close c1
deallocate c1
GO
Example:
use Data_martexecute a procedure:
go
set nocount on
go
drop table dbo.a_table
CREATE TABLE dbo.a_table (
a varchar (50) COLLATE SQL_Latin1_General_CP1_CI_AS
NOT NULL ,
b bigint NOT NULL CONSTRAINT bb DEFAULT (0)
) ON [PRIMARY]
GO
drop function dbo.a_function
go
ALTER FUNCTION dbo.a_function (@one_char nchar(1))
RETURNS nvarchar(50)
AS BEGIN
declare @the_result nvarchar(50)
if @one_char is null set @the_result = ''
else if @one_char = ' ' set @the_result = 'space'
else if 0x0000 <= unicode(@one_char) and unicode(@one_char)
<= 0x007F set @the_result = 'Latin'
else set @the_result = 'unknown (code=' + cast(unicode(@one_char)
as nvarchar(20)) + ')'
return @the_result
END
go
begin
set @the_result = dbo.a_function(@one_char)
if @the_result <> 'Latin' and @the_result <> ''
set @the_result = N'The
character "' + isnull(@one_char,'?') + N'"' + cast(unicode(@one_char) as nvarchar(10))
+ N' is in block ' + @the_result else
set @the_result = N''
return @the_result
end
exec dbo.character_a_function_counts_store
@table_name , @column_name, @country_code, @one_blockexecute a dynamic SQL statement:
set @the_sql = 'declare @one_string nvarchar(300), @country_code varchar(2)'
+ char(13) + char(10) +
'' + char(13) + char(10) +
'Declare c1 cursor scroll for ' + char(13) + char(10)
+
print @the_sql
exec (@the_sql)
More samples
if(@diagramname is null)
begin
RAISERROR ('Invalid value', 16, 1);
return -1
end
EXECUTE AS CALLER
select @theId = DATABASE_PRINCIPAL_ID() -- UNDONE: more work
select @IsDbo = IS_MEMBER(N'db_owner')
if(@owner_id is null)
select @owner_id = @theId
REVERT
DECLARE @CRLF char(2)
SET @CRLF = CHAR(13) + CHAR(10)
SET @Task = 'INSERT #TEMP_TABLE FROM ' + CHAR(39) + ... + CHAR(39) + '...'
-- CHAR(39) is the single quote
EXECUTE (@Task)
SET @Return = @@ERROR
set nocount on |
MS-SQL Server methodology:
schema design --> query optimisation --> indexing --> locking --> server tuning
The first step is to establish a baseline for comparison (include numbers for day-time and batch-time) Use the performance monitor for one instance. Or use third party software for the whole enterprise.
Tools:
Locks: See activity monitor (need "view server state" permission) server in object explorer > management > SQL Server logs > activity monitor
Identify locking and blocking:
SQL Server profiler
-- Flush cache
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
DECLARE @Unit SmallINT
SET @Unit = 1 -- Edit to the current unit
DECLARE @StartTime DateTime
SET @StartTime = getdate()
--execute...
INSERT PerfTest (Unit, Code, Duration )
VALUES (@Unit, 'procedure name', GetDate() - @StartTime)
SELECT Code, [1],[2],[3],[4],[5], [6]
FROM
(Select Unit, Code,
(DatePart(n, Duration) * 60000) +
(DatePart(s,Duration) * 1000) +
DatePart(ms, Duration) as ms
from PerfTest) p
PIVOT
(
avg(ms)
FOR Unit IN ([1],[2],[3],[4],[5], [6])
) AS pvt
ORDER BY Code
Show the execution time
declare @startTime datetime
SET @StartTime = getdate()
exec the_stored_procedure
select 'Execution in milliseconds: ' , datediff(ms, @StartTime, getdate())
Statistics degrade over time. SQL Server determines when it is degraded by over, e.g., 10% and automatically runs the analysis. Sometimes, SQL Server will decide just before running a query that the statistics need updating! Note: run update statistics before establishing a baseline.
Statistics are done only on data.
An intersection is a data point
A slice is a "qualified data reference"
In ANSI92 SQL:
select ...
from
group by ...
with cube
with rollup
This returns aggregation lines in the result.
MSSQLserverOLAPservice is a service (see services)
MOLAP:
can't move the files but backup and restore on another server.
The cube can be read by other tools. But if it is modified, MSsqlOLAP cannot
read it again.
ROLAP: use when the data is fairly static
HOLAP: not really useful
Properties for dimensions are located both in the dimension editor and in the
cube editor
Properties for the measures are only in the cube editor.
Member properties also show in the upper right-hand corner.
Private dimensions have to be edited in the cube editor,
shared dimensions have to be edited outside the cube editor.
Note that member key column may be different than the member name column.
Snowflake with levels:
======================
Use wizard.
The key for the leaf level is probably the ID for the table.
In snowflake design, start with lowest or highest table, not a middle table.
Parent-child dimensions:
========================
They are changing, i.e. if there is a change, the dimension does not have to
be reprocessed.
But this means that the queries are slower because they are not pre-calculated.
Always create with the wizard: member key is the lower level, parent is the
upper level.
Add the member name (generally the name corresponding to the ID).
Property:
Members with data: leaf members only / non-leaf members hidden (bizarre results)
/ non-leaf members visible
Data member caption template: how the non-leaf members are displayed. Empty:
same as other members.
member property "Level Naming Template": when entering with the "...",
click in box next to "*"
member property "skipped_levels": allows the level naming from template
to correspond to levels.
Time dimension
==============
use wizard. Choose "time dimension".
The levels in a time dimension are identified by the "level type"
property of the levels.
Text time: add the same column three times. There is a hierarchy based on the
same column.
Modify the member key first (left(,n) or right(,m) or substring(,n,m)), then
the member name.
Hierarchy of dimensions
=======================
Click the "create hierarchy of dimensions" at the end of the wizard.
dim_name.xyz
for time dimensions, one is the default time dimension, the other is standard.
But make it "time" when creating and then change to standard in the
advanced dimension properties.
Grouping
========
Add the same field, and put for example left(..., 2) in both the key and the
name
If needed, set "hide member if" to "no name". This hides
the blank members.
formulas / functions
====================
convert ID to string for display and concatenation
rtrim(convert(char, "dbo"."Product"."Product_ID"))
+ ' - ' + "dbo"."Product"."Product_Name"
rtrim because the convert adds a space.
Some examples of measures
source column whatever, aggregate function: max --> returns the maximum value
Calculated members:
margin: [Measures].[Warehouse Sales]-[Measures].[Warehouse Cost]
Difference from one year to the next: [Time].[Year].&[1998]-[Time].[Year].&[1997]
Total of USA and Canada: Sum({[Store].[Store Country].&[USA], [Store].[Store
Country].&[Canada]})
SUM(set). The brackets {} return a set of two members.
Average: [Measures].[Store Sales]/[Measures].[Unit Sales]
Average of all members: Avg([Customer].[Customer].Members) (parent member is
the "all")
Time from date: DatePart('yyyy',a date)
DatePart('q',a date)
DatePart('m',a date)
Format (a date, 'mmmm') --> full month
Integer to string: format$()
member properties
=================
member properties of members show in the upper right-hand corner when browsing.
Note that these virtual dimensions are not stored in the cude (no storage space)
but have
to be extracted each time. So use for adhoc queries.
Create a member property by dragging a field in the "member properties"
below the member name.
Virtual dimensions
==================
First create the member property, or click "Display member keys and names"
in the wizard
Wizard is best for creating virtual dimensions.
A virtual dimension can be transformed into a non-virtual dimension (I guess
that this means
that the aggregation values get stored in the database)
A virtual dimension always has a value for the "depends on dimension"
Another way is to create a virtual dimension:
- define the "Depends on Dimension" D
- set the value of the dimension to the field which is the member property in
dimension D
- set "virtual" property to true
Types of dimensions
- star schema
- snowflake
- parent-child
- virtual dimension
- (mining model)
Dimension Properties
Top level:
All level. If yes, one last aggregation is shown. The caption is defined in
property "All Caption".
Type: more of an indication than a real way to change properties.
Default member: often empty. Put the member that is displayed by default.
Depends on dimension: "(none)". Used for virtual dimensions.
Changing: Generally false.
True for example for parent-child dimensions
Write-enabled: false generally
Member keys unique: if true, the processing can be faster
Member names unique: if true, the processing can be faster
Allow duplicate names:
Source table filter:
Storage mode: MOLAP, ROLAP or hybrid
Enable real-time updates:
Virtual: if true, indicates a virtual dimension (see above).
The aggregates are not stored in the cube.
All member formula.
Members with data: see parent-child
Data Member Caption template.
Double quotes around table and field names, single quotes around the strings.
"customer"."lname" + ', ' + "customer"."fname"
+ ' ' + "customer"."mi"
Count mesaure: add the key/ID to the measures, and set the
aggregate function to count or distinct count.
One table has several fields, which constitue a hierarchy:
start with highest in hierarchy (or leaf/lowest level), not the middle level.
Create the dimension. Then drag and drop the the other fields in.
Unary operator:
===============
if true, a field is defined for the rollup.
The field, which is stored in the database, should contain +, / or ~.
Use this in a child-parent dimension. The unary operators property is on the
level.
Storage
=======
1) Type of storage: MOLAP, ROLAP or hybrid.
2) Aggregation options:
The tool sets the aggregation options (but aggregation is actually calculated
when
the cube is processed). The processing will build aggregates until either all
aggregates
have been built, or the maximum size is reached (storage option), or the until
a percentage
of performance is reached (start with 10% and increase if querying the cube
is too slow,
i.e. there is not enough aggregation, generally 50% is enough) or until click
(watch when
the performance gain levels off in the graph).
3) Save the options for processing later or process now.
Updating
========
Updating dimension data.
If new data is available for the dimension, i.e. new rows in the dimension source
table,
I can add it incrementally. The advantage is that the cubes do not have to be
fully
reprocessed. Just after an incremental process of the dimension, the new data
shows
in the cube in the dimensions, but with no facts. In this case, process the
cube with the
refresh option.
Before re-processing, the ROLAP cube will show the updated detail at the lowest
level, but
not any change in aggregations. The aggregations do not correspond to the details,
because
the details are retrieved directly from the relational tables.
An incremental processing of the cube (not dimensions) using the "normal"
source data
will in effect double all measures. If this is done, refresh the cube so as
to get
the correct data again.
The big question: refresh or incrementally update
Refresh: remove and redo everything
Incremental: add to existing data
One option, if I can control what is being added to the dimension.
Suppose that I incrementally update the dimension and I know that I am adding
element X
So I incrementally update the dimension D then I incrementally update the cube
with a filter
on D='X' so as to only add the new data and I do not have to refresh the whole
cube.
However, I have to know which members are new to the dimension.
It is smart to always keep the original RDBMS fact tables, even if it is on a tape.
Optimize
========
Define the member key as the foreign key in the fact table instead of the
primary key in the reference table. Do this in the cube editor: menu tools >
optimize
This can only be done with shared dimensions. Private dimensions do not work
this way.
Partitions
==========
It is smart to always keep the original RDBMS fact tables, even if it is on a tape.
Each partition has separate storage and storage characteristics.
N.B. Options exist to define both slice and partition filters. Confusing mix:
be careful.
Drill-through is also defined differently for each partition.
Processing is done partition by partition.
View the slices used in the metadata. The edit forces a re-design of the partition.
The filter info has to be viewed with the editor. Just click cancel at the end.
In merging partitions, be careful in the cases when the source data is from different tables.
Partitions can be dropped easily
Partitions cannot be renamed. I created a new partition and dropped the original
one.
It is useful to use drill through with partitions. Drill through are less useful
without partitions
because actions are equivalent to drill through if there are no partitions.
Calculated members
==================
In cube editor
Note that adding a calculated member does not need a re-processing of the cube.
Compare one year to another in time dimension: create a calculated member in
the time dimension as (2001)-(2000). This member will calculate measures for
2001 minus values for 2000.
Examples:
Avg([Product].[Category].Members)
Sum([Product].[Subcategory].Members)/Count([Product].[Category].Members) (equivalent
to average)
Sum({[Store].[Store Country].&[USA],[Store].[Store Country].&[Canada]})
Virtual Cubes
==============
Cubes in the virtual cube must have at least one dimension in common.
Rename measure names with F2
Pivot tables in Excel
====================
Menu data > pivot table and chart
Option "external data source"
Get data: tab "OLAP cubes". New data source. Provider "...OLAP
Services 8.0"
Choose the analysis server option and enter the server name (localhost). UserID
blank.
Create local data cube with "client-server" options in the pivot table
drop-down menu.
Actions
=======
For example: HTML "<html><head>...." + dimension_name.currentmember.properties
+ ".href=""literal with two double quotes""....."
+ dimension_name.currentmember.name + "...</html>"
To a certain extent, actions are similar to drill through (when there are no
partitions)
Write-back
==========
A separate table stores the delta. The original data is not modified. The client
displays
the values from the cube plus the deltas from the write-back table.
There is an option to merge write-back data into a new partition: old partition
plus write-back deltas.
SQL Server does the following:
parse statement, then resolve, optimize (determine the execution plan), compile
and execute.
After compilation, kept in procedure cache, so subsequent execution skips all
up to the compilation.
Add query plans to the source control (query plans from test then from production server) so as to have a baseline for comparing back to.
Database engine tuning advisor is the indexing wizard
DDL (create, alter, drop)
DCL (data control language, grant, deny, revoke)
DML (.. manipulation)
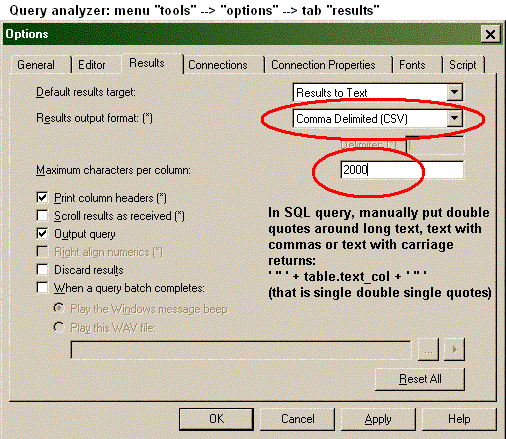
CSV formatted output in Query Analyzer: menu > tools > options > tab "results".
Choose "results to text" in the "default output format".
Then choose "Comma Delimited" in the "Results Output Format". Make sure that the
number in the "Maximum Characters per Column" is larger than the longest string.
In the SQL query, manually put double quotes around long text, text that could contain commas or
carriage returns with:
"'" + table.text_col + "'" -- That is double quote, single quote, double quote
SQL Server's solution for full text indexing. Requires:
Putting a single-column primary key (or unique key column) on tables
Full-text index, which keeps track of the significant words in the texts. Reside
on file system.
Full-text catalogs: collections of full-text indexes. They reside on the file
system. One or more catalogs per database.
See documentation about stored procedures and properties.
WHERE CONTAINS (column_name, 'expression')
WHERE FREETEXT (column_name, 'free text')
WHERE CONTAINSTABLE (table, column_name, 'expression')
WHERE FREETEXTTABLE (table, column_name, 'free text')
osql -? --> syntax
Example: osql -S "SERVER" -E -i "script_file.sql"
osql -S "SCDW002" -E -i "glu.sql"
osql -E -Q "the SQL" -o "C:\Program Files\Microsoft SQL Server\File.fmt" -s "" -w 8000
Use osql.exe like SQL*Plus
osql -S "MIA-SQL\SQLINST1" -E -Q "create database Accounts
ON(FILENAME='E:\Labfiles\Starter\Preparation\Accounts.mdf')
LOG ON (FILENAME='E:\Labfiles\Starter\Preparation\Accounts_Log.ldf')
FOR ATTACH"
osql -S "MIA-SQL\SQLINST1" -E -Q "EXECUTE sp_detach_db 'Accounts'"
sqlcmd -E -S MIA-SQL\SQLINST1 -i "UT Create Orders.sql"
Notification Service
The suscriptions define who gets notified.
DECLARE @XMLDepartments XML;
SET @XMLDepartments =
'<Departments>
<Department Name="Accounting">
<GroupName>Executive General and Administration</GroupName>
</Department>
<Department Name="International Sales">
<GroupName>Sales and Marketing</GroupName>
</Department>
<Department Name="Software Development">
<GroupName>Research and Development</GroupName>
</Department>
</Departments>';
SELECT Doc.Dep.value('@Name', 'NVARCHAR(50)') AS DeparmentName,
Doc.Dep.value('GroupName[1]','NVARCHAR(50)') AS GroupName
FROM @XMLDepartments.nodes('//Departments/Department') AS Doc(Dep);
--DeparmentName GroupName
---------------------------------------------------- --------------------------------------------------
--Accounting Executive General and Administration
--International Sales Sales and Marketing
--Software Development Research and Development
--
--(3 row(s) affected)
--
DECLARE @docHandle INT;
EXEC sp_xml_preparedocument @docHandle OUTPUT, @XMLDepartments;
SELECT * FROM OPENXML(@docHandle, '//Departments/Department')
WITH (DeparmentName NVARCHAR(50) '@Name',
GroupName NVARCHAR(50) 'GroupName');
--DeparmentName GroupName
---------------------------------------------------- --------------------------------------------------
--Accounting Executive General and Administration
--International Sales Sales and Marketing
--Software Development Research and Development
--
--(3 row(s) affected)
--